一、简介
最近公司的服务要升级,需要一个新的小文件存储系统,用来存储服务产生的3000万文件,文件大小在 20-80KB之间。 于是就有了 sfs。
sfs 是 small file storage 的简写, 意在提供小文件的存储,目前文件大小上限为 10MB. 底层存储 seaweedfs 作为存储引擎. seaweedfs 以 volume 为存储单元, 将多个文件连续存入 volume 直到 volume 满, 之后 volume 切换为 readonly 状态. 这样做的好处是避免讲小文件以单个文件的形式存储至文件系统, 减少文件系统元数据的维护成本(内存消耗大, 缓存命中率低等). sfs 可以支持亿级的小文件存储.
之前老旧系统使用的 fastdfs 作为存储, 由于没有对 fastdfs 进行深入的了解, 在此不做优劣比较. 但目前系统存在的最大问题是可控性差,因为之前旧系统使用的是 nginx + php + fastdfs 搭建, 而团队无人熟悉php开发, 要做定制化的时候很棘手. 之前也考虑用 golang + fastdfs 重构, 但 fastdfs 的 api 比较复杂, 不好与golang交互.
从目前对 seaweedfs (版本 0.76) 了解来看, 有如下优点:
- 代码简洁, 团队主要开发语言是 golang + cpp, 目前看懂全部源码无障碍.
- 部署简单方便. master, volume 只需要在命令行设置命令即可.
- 可操控性高, 虽然目前 seaweedfs 在运维方面没有自动化, 但架构简单带来低运维成本.
- 以 restful 提供 API, 定制方面很方便.
- 支持跨主机, 跨机柜, 跨机房的复制(replication), 而且是强一致性.
- 支持文件删除, 并能自动回收被删除文件所占用的空间.
当然, seaweedfs 也有不足:
- 貌似都是作者一个人在贡献代码, 作者已经持续开发两三年了, 看起来很用心, 但也导致新bug没有及时修复.
- 复制(replication) 只有在写入的时候支持, 之后如果发生副本丢失, 需要手动介入修复. 例如文件 F 写入后分别在 A, B 两个节点. 假如 A 挂了, B则切换为 readonly 状态, 但 seaweedfs 并不会自动为 A 找新的替代节点, 只能手动从 B 复制到 A’,再启动 A’ 才能完成故障修复.
- 缺乏分布式事务. 如果文件写入的时候开启了复制,例如 replication=100 表示在两个机房分别存放. 例如选择A, B 两个不同机房的节点, 写入操作流程是先写入A, 再写入B, 如果写入B失败,则整个写入操作 当做失败处理, 但是此时并不会删除已经写入A的那部分, 这部分就永远被保存在 volume 中, 也不会被垃圾回收, 这一点在应用的时候需要特别注意. 作者当前给的建议是如果失败, 则重试的时候要使用原先的 fid, 不在再另外 assign 一个新的, 否则会导致垃圾越来越多, 这些垃圾成了存储的黑洞.
- 目前多 Master 部署时还有脑裂的情况, 会导致数据相互覆盖.https://github.com/chrislusf/seaweedfs/issues/418
二、架构
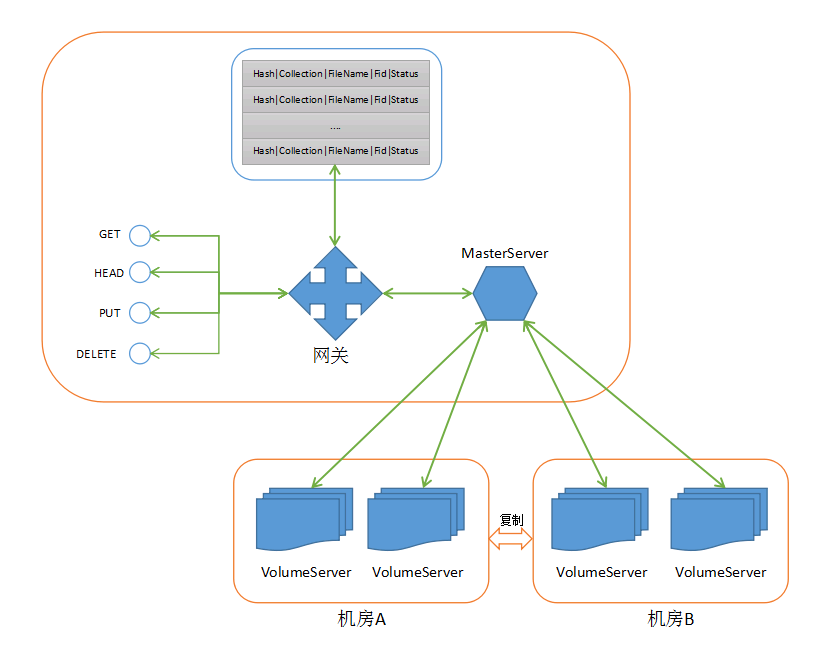
业务隔离
sfs 使用 seaweedfs 提供的 collection 实现, seaweedfs 会将不同的 collection 分开存储到不同 volume, 日后在做迁移或者物理隔离(分集群)就很方便,只要将对应 volume 复制过去即可. API 上通过 collection 进行隔离.
文件存储和元数据存放在MySQL
由于文件数量很大, 对 filename 进行crc32计算,再取模 32 放到32个不同的表, 每张表再加 collection 列进行业务隔离.
解决上面 不足 的第3点
上面提到写入失败留下脏数据的问题, 解决方法是每次 assign 得到 fid 之后, 在 mysql 中保存 fid 和 <filename, collection> 的关系, 同时在 MySQL 中用 status 标记文件的状态, 0表示未上传, 1表示已上传成功.
这样避免重试上传的时候都产生新的 fid 而留下脏数据.
三、授权和认证
每个 collection 需要注册 appid 和 对应的 secretkey,请求是带上 sign 进行认证。
四、API 说明
sfs 文件操作都通过 restful 暴露给客户端, http://xxx/storage/v1/sfs
1. 查询接口(HEAD)
curl 'http://xxxx/storage/v1/sfs?name=test.json&collection=xxx'
请求参数
| 参数名 | 是否必填 | 说明 |
|---|---|---|
| name | 是 | 文件名 |
| collection | 是 | 代表不同的业务,如 audio, video, image |
| appid | 是 | 应用ID,统一分配 |
| ts | 是 | 请求时的unix时间戳(秒), 请求有效时间为15分钟 |
| sign | 是 | sign=md5(name + collection + appid + ts + secretkey) |
响应参数
响应参数都在 http 头部
| 参数 | 说明 |
|---|---|
| X-Sfs-Hash | 文件的hash,在上传时sfs网关会自动计算文件md5作为hash |
| X-Sfs-Size | 文件字节大小 |
| X-Sfs-Metadata | 文件相关的元数据,在文件上传时指定 |
| X-Sfs-Fid | 文件在 seaweedfs 中的 fid |
| X-Sfs-Status | 文件状态, 0 - 未上传,1 - 已成功上传 |
| X-Sfs-Addtime | 文件成功上传的时间 |
| X-Sfs-Url | 文件下载地址 |
错误码
| 错误码 | 说明 |
|---|---|
| 200 | 文件存在, 请求成功 |
| 400 | 参数错误 |
| 401 | 未认证 |
| 404 | 文件不存在 |
| 500 | 服务异常 |
2. 读取文件接口(GET)
请求参数和响应参数与 HEAD 相同, 只是 http body 会返回文件的内容。
3. 上传/更新文件接口(POST/PUT)
请求参数
文件上传时 http 头部必须带上 Content-Length 标识文件的大小, 目前最大支持 10MB。
| 参数 | 是否必填 | 说明 |
|---|---|---|
| name | 是 | 文件名 |
| collection | 是 | 代表不同业务 |
| appid | 是 | 应用ID,统一分配 |
| ts | 是 | 请求时的unix时间戳(秒), 请求有效时间为15分钟 |
| sign | 是 | sign=md5(name + collection + appid + ts + secretkey) |
| hash | 否 | 文件hash,sfs网关在接收文件之后会做校验,如果和文件的hash对不上则报错,也可以通过头部 X-Sfs-Hash 传输 |
| metadata | 否 | 文件相关的元数据,建议不要超过1k,也可以通过头部 Sfs-Metadata 传输 |
响应参数
与 HEAD, GET 一致.
错误码
| 错误码 | 说明 |
|---|---|
| 200 | 文件存在, 请求成功 |
| 400 | 参数错误 |
| 401 | 未认证 |
| 404 | 文件不存在 |
| 411 | 缺少 Content-Length 头 |
| 413 | 文件太大,超过上限 |
| 500 | 服务异常 |
4. 删除接口
请求参数
| 参数名 | 是否必填 | 说明 |
|---|---|---|
| name | 是 | 文件名 |
| collection | 是 | 代表不同的业务,如 audio, video, image |
| appid | 是 | 应用ID,统一分配 |
| ts | 是 | 请求时的unix时间戳(秒), 请求有效时间为15分钟 |
| sign | 是 | sign=md5(name + collection + appid + ts + secretkey) |
响应参数
错误码
| 错误码 | 说明 |
|---|---|
| 200 | 文件存在, 请求成功 |
| 400 | 参数错误 |
| 401 | 未认证 |
| 404 | 文件不存在 |
| 500 | 服务异常 |
性能
为了避免 gateway 成为瓶颈, 可以使用 HEAD 从响应头部读取 X-Sfs-Url, 之后再通过 http GET 下载文件.
